数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据
线性表: 线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构
非线性表: 二叉树、堆、图等, 在非线性表中,数据之间并不是简单的前后关系
连续的内存空间和相同类型的数据。正是因为这两个限制,它才有了一个堪称“杀手锏”的特性:“随机访问”
但有利就有弊,这两个限制也让数组的很多操作变得非常低效
容器能否完全替代数组?
- ArrayList 最大的优势就是可以将很多数组操作的细节封装起来
- 还有一个优势,就是支持动态扩容
- Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗
- 当要表示多维数组时,用数组往往会更加直观
- 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组
为什么大多数编程语言中,数组要从 0 开始编号,而不是从 1 开始呢?
计算 a[k] 的内存地址只需要用这个公式:
a[k]_address = base_address + k * type_size
如果数组从 1 开始计数,那我们计算数组元素 a[k] 的内存地址就会变为:
a[k]_address = base_address + (k-1)*type_size
从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令
当然,也可能有一些历史原因:
C 语言设计者用 0 开始计数数组下标,之后的 Java、JavaScript 等高级语言都效仿了 C 语言,或者说,为了在一定程度上减少 C 语言程序员学习 Java 的学习成本,因此继续沿用了从 0 开始计数的习惯。实际上,很多语言中数组也并不是从 0 开始计数的,比如 Matlab。甚至还有一些语言支持负数下标,比如 Python。
链表
单链表
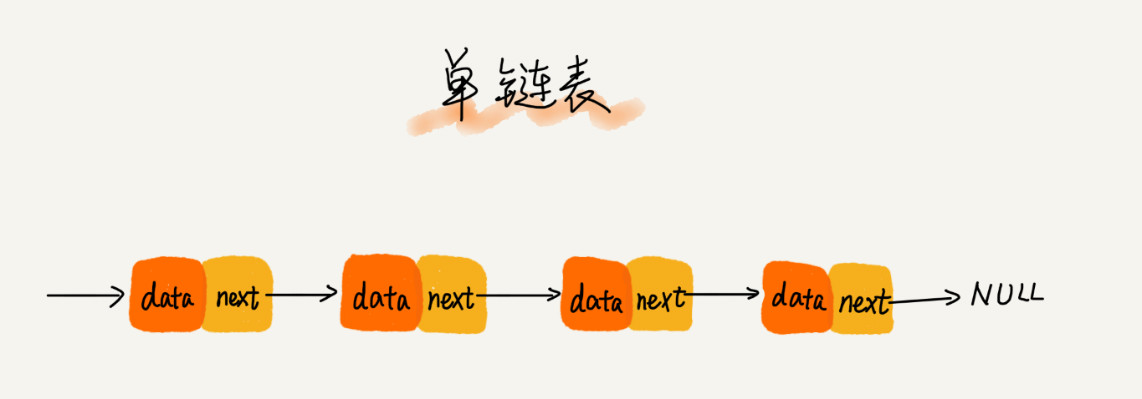
我们习惯性地把第一个结点叫作头结点,把最后一个结点叫作尾结点。
其中,头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。
而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点
链表要想随机访问第 k 个元素,就没有数组那么高效了。
因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点
循环链表和双向链表
循环链表是一种特殊的单链表。实际上,循环链表也很简单。它跟单链表唯一的区别就在尾结点, 循环链表的尾结点指针是指向链表的头结点
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表
而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
如果你的代码对内存的使用非常苛刻,那数组就更适合你。因为链表中的每个结点都需要消耗额外的存储空间去存储一份指向下一个结点的指针,所以内存消耗会翻倍。而且,对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)
解题技巧
- 理解指针或引用的含义
有些语言有“指针”的概念,比如 C 语言;有些语言没有指针,取而代之的是“引用”,比如 Java、Python。
不管是“指针”还是“引用”,实际上,它们的意思都是一样的,都是存储所指对象的内存地址
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量
- 警惕指针丢失和内存泄漏
对于有些语言来说,比如 C 语言,内存管理是由程序员负责的,如果没有手动释放结点对应的内存空间,就会产生内存泄露。
同理,删除链表结点时,也一定要记得手动释放内存空间,否则,也会出现内存泄漏的问题。当然,对于像 Java 这种虚拟机自动管理内存的编程语言来说,就不需要考虑这么多了
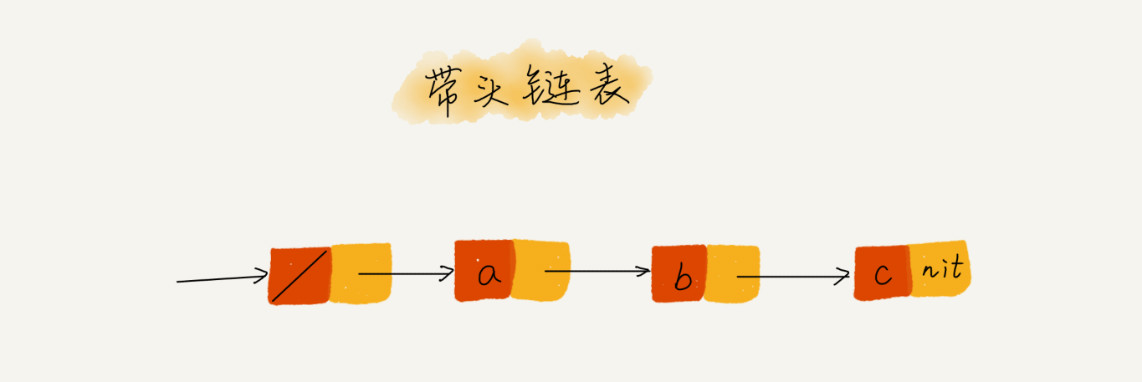
- 利用哨兵简化实现难度
可以看出,针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。
- 重点留意边界条件处理
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
-
举例画图,辅助思考
-
多写多练,没有捷径
常见的链表操作:
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
栈
后进者先出,先进者后出,这就是典型的“栈”结构
事实上,从功能上来说,数组或链表确实可以替代栈,但你要知道,特定的数据结构是对特 定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时 就比较不可控,自然也就更容易出错。
栈的实现
实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序 栈,用链表实现的栈,我们叫作链式栈
数组实现栈
// 基于数组实现的顺序栈
public class ArrayStack {
private String[] items; // 数组
private int count; // 栈中元素个数
private int n; // 栈的大小
// 初始化数组,申请一个大小为 n 的数组空间
public ArrayStack(int n) {
this.items = new String[n];
this.n = n;
this.count = 0;
}
// 入栈操作
public boolean push(String item) {
// 数组空间不够了,直接返回 false,入栈失败。
if (count == n) return false;
// 将 item 放到下标为 count 的位置,并且 count 加一
items[count] = item;
++count;
return true;
}
// 出栈操作
public String pop() {
// 栈为空,则直接返回 null
if (count == 0) return null;
// 返回下标为 count-1 的数组元素,并且栈中元素个数 count 减一
String tmp = items[count-1];
--count;
return tmp;
}
}
栈的应用
- 函数调用栈
- 表达式求值
- 括号匹配
- …
队列
先进者先出,这就是典型的“队列”
所以,队列跟栈一样,也是一种操作受限的线性表数据结构
队列实现
数组实现队列
// 用数组实现的队列
public class ArrayQueue {
// 数组:items,数组大小:n
private String[] items;
private int n = 0;
// head 表示队头下标,tail 表示队尾下标
private int head = 0;
private int tail = 0;
// 申请一个大小为 capacity 的数组
public ArrayQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队操作,将 item 放入队尾
public boolean enqueue(String item) {
// tail == n 表示队列末尾没有空间了
if (tail == n) {
// tail ==n && head==0,表示整个队列都占满了
if (head == 0) return false;
// 数据搬移
for (int i = head; i < tail; ++i) {
items[i-head] = items[i];
}
// 搬移完之后重新更新 head 和 tail
tail -= head;
head = 0;
}
items[tail] = item;
++tail;
return true;
}
// 出队
public String dequeue() {
// 如果 head == tail 表示队列为空
if (head == tail) return null;
// 为了让其他语言的同学看的更加明确,把 -- 操作放到单独一行来写了
String ret = items[head];
++head;
return ret;
}
}
循环队列
public class CircularQueue {
// 数组:items,数组大小:n
private String[] items;
private int n = 0;
// head 表示队头下标,tail 表示队尾下标
private int head = 0;
private int tail = 0;
// 申请一个大小为 capacity 的数组
public CircularQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enqueue(String item) {
// 队列满了
if ((tail + 1) % n == head) return false;
items[tail] = item;
tail = (tail + 1) % n;
return true;
}
// 出队
public String dequeue() {
// 如果 head == tail 表示队列为空
if (head == tail) return null;
String ret = items[head];
head = (head + 1) % n;
return ret;
}
}
阻塞队列
阻塞队列其实就是在队列基础上增加了阻塞操作。简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回
我们可以使用阻塞队列,轻松实现一个“生产者 - 消费者模型”!
这种基于阻塞队列实现的“生产者 - 消费者模型”,可以有效地协调生产和消费的速度
并发队列
实际上,基于数组的循环队列,利用 CAS 原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因
对于大部分资源有限的场景,当没有空闲资源时,基本上都可以通过“队列”这种数据结构来实现请求排队