
什么是正则
正则就是用有限的符号,表达无限的序列
- 用来描述或者匹配一系列符合某个语句规则的字符串
语法
单个符号
- 英文句点
.符号:匹配单个任意字
表达式
t.o可以匹配:tno,t#o,teo等等。不可以匹配:tnno,to,Tno,t正o等
- 中括号
[]:只有方括号里面指定的字符才参与匹配,也只能匹配单个字符
表达式:
t[abcd]n只可以匹配:tan,tbn,tcn,tdn。不可以匹配:thn,tabn,tn
|符号。相当与“或”,可以匹配指定的字符,但是也只能选择其中一项进行匹配
表达式:
t(a|b|c|dd)n只可以匹配:tan,tbn,tcn,tddn。不可以匹配taan,tn,tabcn等
- 表示匹配次数的符号
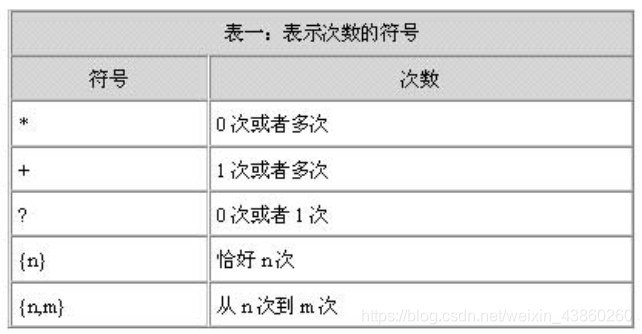
表达式:
[0—9]{ 3 } \— [0-9]{ 2 } \— [0-9]{ 3 }的匹配格式为:999—99—999因为—符号在正则表达式中有特殊的含义,它表示一个范围,所以在前面加转义字符\
^符号:表示否,如果用在方括号内,^表示不想匹配的字符
表达式:
[^x]第一个字符不能是x
\S符号:非空字符\s符号:空字符,只可以匹配一个空格、制表符、回车符、换页符,不可以匹配自己输入的多个空格\r符号:空格符,与\n、\tab相同
快捷符号
\d表示[0—9]\D表示[^0—9]\w表示[0—9A—Z_a—z]\W表示[^0—9A—Z_a—z]\s表示[\t\n\r\f]\S表示[^\t\n\r\f]
常用正则表达式
-
匹配中文字符的正则表达式:
[\u4e00-\u9fa5] -
匹配双字节字符(包括汉字在内):
[^\x00-\xff] -
匹配空行的正则表达式:
\n[\s| ]*\r -
匹配HTML标记的正则表达式:
/<(.*)>.*<\/\1>|<(.*) \/>/ -
匹配首尾空格的正则表达式:
(^\s*)|(\s*$) -
匹配IP地址的正则表达式:
/(\d+)\.(\d+)\.(\d+)\.(\d+)/g // -
匹配Email地址的正则表达式:
\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* -
匹配网址URL的正则表达式:
http://(/[\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)? -
sql语句:
^(select|drop|delete|create|update|insert).*$ -
非负整数:
^\d+$ -
正整数:
^[0-9]*[1-9][0-9]*$ -
非正整数:
^((-\d+)|(0+))$ -
负整数:
^-[0-9]*[1-9][0-9]*$ -
整数:
^-?\d+$ -
非负浮点数:
^\d+(\.\d+)?$ -
正浮点数:
^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ -
非正浮点数:
^((-\d+\.\d+)?)|(0+(\.0+)?))$ -
负浮点数:
^(-((正浮点数正则式)))$ -
英文字符串:
^[A-Za-z]+$ -
英文大写串:
^[A-Z]+$ -
英文小写串:
^[a-z]+$ -
英文字符数字串:
^[A-Za-z0-9]+$ -
英数字加下划线串:
^\w+$ -
E-mail地址:
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ -
URL:
^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$ 或者:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~@[\]\':+!]*([^<>\"\"])*$ -
邮政编码:
^[1-9]\d{5}$ -
提取信息中的网络链接:
(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)? -
提取信息中的邮件地址:
\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* -
提取信息中的图片链接:
(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)? -
提取信息中的IP地址:
(\d+)\.(\d+)\.(\d+)\.(\d+) -
提取信息中的中国手机号码:
(86)*0*13\d{9} -
提取信息中的中国固定电话号码:
(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8} -
提取信息中的中国电话号码(包括移动和固定电话):
(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14} -
提取信息中的中国邮政编码:
[1-9]{1}(\d+){5} -
提取信息中的浮点数(即小数):
(-?\d*)\.?\d+ -
提取信息中的任何数字 :
(-?\d*)(\.\d+)? -
IP地址:
(\d+)\.(\d+)\.(\d+)\.(\d+) -
电话区号:
/^0\d{2,3}$/ -
腾讯QQ号:
^[1-9]*[1-9][0-9]*$ -
帐号(字母开头,允许5-16字节,允许字母数字下划线):
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ -
中文、英文、数字及下划线:
^[\u4e00-\u9fa5_a-zA-Z0-9]+$
Java中的应用
- 判断
public boolean matches(String regex)
public class RegexDm {
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
System.out.println("请输入手机好:");
String s = sc.nextLine();
String regex = "1[38]\\d{9}";//定义手机好规则
boolean flag = s.matches(regex);//判断功能
System.out.println("flag:"+flag);
}
}
- 分割
public String[] split(String regex)
public class RegexDm {
public static void main(String[] args){
String age = "18-24";//定义年龄范围
String regex = "-";
String[] strArr = age.split(regex);//分割成字符串数组
int startAge = Integer.parseInt(strArr[0]);
int endAge = Integer.parseInt(strArr[1]);
Scanner sc = new Scanner(System.in);
System.out.println("请输入您的年龄:");
int a = sc.nextInt();
if (a >= startAge && a <= endAge){
System.out.println("你就是我想找的");
}else{
System.out.println("滚");
}
}
}
- 替换
public String replaceAll(String regex,String replacement)
public class RegexDm {
public static void main(String[] args){
String s = "12342jasfkgnas234";
//把字符串里面的数字替换成*
String regex = "\\d";
String ss = "*";
String result = s.replaceAll(regex,ss);
System.out.println(result);
}
}
拓展
Ant表达式
- 通配符
?:匹配单个字符*:匹配0或多个字符**:匹配0或多个目录
- 示例
/a/*: 匹配 /a/ 下的所有路径,不递归,如: /a/b,/a/c,但不包括/a/b/c/a/**: 匹配 /a/ 下所有路径,递归,如 :/a/b,/a/b/c,/a/b/c/d/a/a?c: 匹配/a/ 下路径中a开头,c结尾,中间按含任意字符的路径,如:/a/adc/app/*.x: 匹配(Matches)所有在app路径下的.x文件/app/p?ttern: 匹配(Matches) /app/pattern 和 /app/pXttern,但是不包括/app/pttern/**/example: 匹配(Matches) /app/example, /app/foo/example, 和 /example/app/**/dir/file.*: 匹配(Matches) /app/dir/file.jsp, /app/foo/dir/file.html,/app/foo/bar/dir/file.pdf, 和 /app/dir/file.java/**/*.jsp: 匹配(Matches)任何的.jsp 文件
最长匹配原则(has more characters): 说明,URL请求/app/dir/file.jsp,现在存在两个路径匹配模式
/**/*.jsp和/app/dir/*.jsp,那么会根据模式/app/dir/*.jsp来匹配