Elasticsearch 简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况
使用您自己的编程语言与 Elasticsearch 进行交互
Elasticsearch 使用的是标准的 RESTful 风格的 API 和 JSON。此外,我们还构建和维护了很多其他语言的客户端,例如 Java、Python、.NET、SQL 和 PHP。与此同时,我们的社区也贡献了很多客户端。这些客户端使用起来简单自然,而且就像 Elasticsearch 一样,不会对您的使用方式进行限制
Java:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("localhost", 9200, "http")));
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(AggregationBuilders.terms("top_10_states").field("state").size(10));
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("social-*");
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
ElasticSearch安装参照Docker安装ElasticSearch
快速入门
基础概念
- 节点 Node、集群 Cluster 和分片 Shards
ElasticSearch 是分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个实例。单个实例称为一个节点(node),一组节点构成一个集群(cluster)。分片是底层的工作单元,文档保存在分片内,分片又被分配到集群内的各个节点里,每个分片仅保存全部数据的一部分。
- 索引 Index、类型 Type 和文档 Document
对比我们比较熟悉的 MySQL 数据库:
index → db type → table document → row
如果我们要访问一个文档元数据应该包括囊括 index/type/id 这三种类型,很好理解。
使用 RESTful API 与 Elasticsearch 进行交互
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
- 查询所有
GET /_count?pretty
{
"query": {
"match_all": {}
}
}
- 增加文档
POST /db/user/1
{
"username": "wmyskxz1",
"password": "123456",
"age": "22"
}
POST /db/user/2
{
"username": "wmyskxz2",
"password": "123456",
"age": "22"
}
- 删除
DELETE /db/user/1
- 修改
PUT /db/user/2
{
"username": "wmyskxz3",
"password": "123456",
"age": "22"
}
- 查询
GET /db/user/2
核心功能:搜索
- _search端点
搜索请求正文和ElasticSearch查询DSL
{
"query": {
//Query DSL here
}
}
基本自由文本搜索:
GET /_search
{
"query": {
"query_string": {
"query": "kill"
}
}
}
指定搜索的字段
GET /_search
{
"query": {
"query_string": {
"query": "ford",
"fields": [
"title"
]
}
}
}
过滤
GET /_search
{
"query": {
"query_string": {
"query": "drama"
}
}
}
//添加过滤器
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
//Filter to apply to the query
}
}
}
}
"filter": {
"term": { "year": 1962 }
}
Spring Boot 集成ElasticSearch
- 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Elasticsearch支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 配置文件
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
- 实体类
@Document(indexName = "users", type = "user")
public class User {
private int id;
private String username;
private String password;
private int age;
/** getter and setter */
}
- Dao层
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface UserDao extends ElasticsearchRepository<User, Integer> {
}
- Controller层
@RestController
public class UserController {
@Autowired
UserDao userDao;
@PostMapping("/addUser")
public String addUser(String username, String password, Integer age) {
User user = new User();
user.setUsername(username);
user.setPassword(password);
user.setAge(age);
return String.valueOf(userDao.save(user).getId());// 返回id做验证
}
@DeleteMapping("/deleteUser")
public String deleteUser(Integer id) {
userDao.deleteById(id);
return "Success!";
}
@PutMapping("/updateUser")
public String updateUser(Integer id, String username, String password, Integer age) {
User user = new User();
user.setId(id);
user.setUsername(username);
user.setPassword(password);
user.setAge(age);
return String.valueOf(userDao.save(user).getId());// 返回id做验证
}
@GetMapping("/getUser")
public User getUser(Integer id) {
return userDao.findById(id).get();
}
@GetMapping("/getAllUsers")
public Iterable<User> getAllUsers() {
return userDao.findAll();
}
}
其实使用 SpringBoot 来操作 Elasticsearch 的话使用方法有点类似 JPA 了,而且完全可以把 Elasticsearch 当做 SQL 服务器来用,也没有问题…在各种地方看到了各个大大特别是官方,都快把 Elasticsearch 这款工具吹上天了,对于它方便的集成这一点我倒是有感受,关于速度这方面还没有很深的感受,慢慢来吧…
倒排索引
Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤。特别是它对多条件的过滤支持非常好

这里有好几个概念。我们来看一个实际的例子,假设有如下的数据:
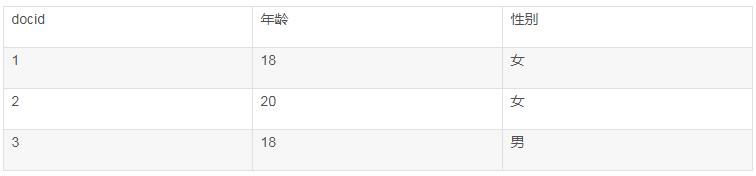
这里每一行是一个document。每个document都有一个docid。那么给这些document建立的倒排索引就是:
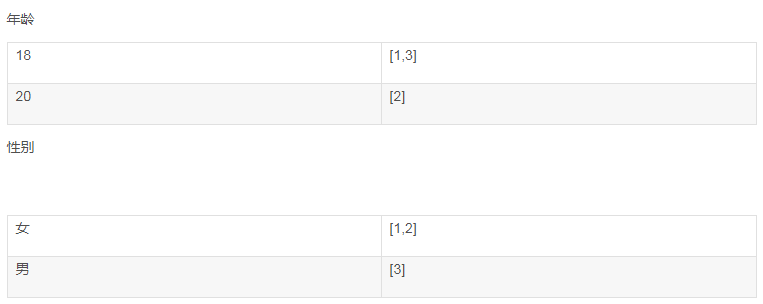
可以看到,倒排索引是per field的,一个字段由一个自己的倒排索引。18,20这些叫做 term,而[1,3]就是posting list。Posting list就是一个int的数组,存储了所有符合某个term的文档id。那么什么是term dictionary 和 term index?
假设我们有很多个term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的term一定很慢,因为term没有排序,需要全部过滤一遍才能找出特定的term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的term。这个就是 term dictionary。有了term dictionary之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次random access大概需要10ms的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个term dictionary本身又太大了,无法完整地放到内存里。于是就有了term index。term index有点像一本字典的大的章节表。比如:
A开头的term ……………. Xxx页
C开头的term ……………. Xxx页
E开头的term ……………. Xxx页
如果所有的term都是英文字符的话,可能这个term index就真的是26个英文字符表构成的了。但是实际的情况是,term未必都是英文字符,term可以是任意的byte数组。而且26个英文字符也未必是每一个字符都有均等的term,比如x字符开头的term可能一个都没有,而s开头的term又特别多。实际的term index是一棵trie 树
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有term的尺寸的几十分之一,使得用内存缓存整个term index变成可能。整体上来说就是这样的效果。
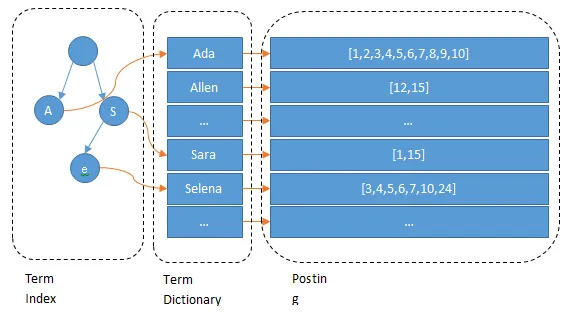
现在我们可以回答“为什么Elasticsearch/Lucene检索可以比mysql快了。Mysql只有term dictionary这一层,是以b-tree排序的方式存储在磁盘上的。检索一个term需要若干次的random access的磁盘操作。而Lucene在term dictionary的基础上添加了term index来加速检索,term index以树的形式缓存在内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘的random access次数。
额外值得一提的两点是:term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary可以比b-tree更节约磁盘空间。